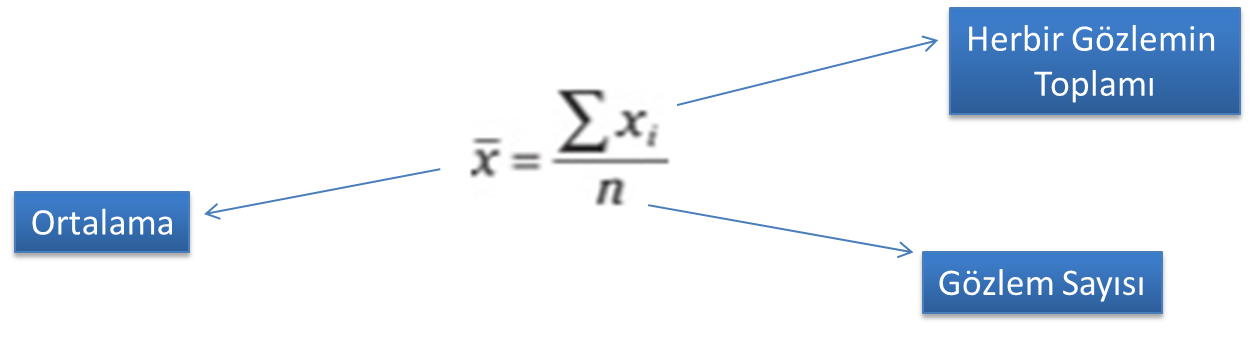Rassal Değişken
Bir deney ya da gözlemin şansa bağlı sonucu bir değişkenin aldığı sonuç olarak düşünülürse, olasılık ve istatistikte böyle bir değişkene rassal değişken denir. Rassal değişkenler Kesikli ve Sürekli olmak üzere ikiye ayrılır.Kesikli Rassal Değişken
Eğer rassal değişkenin sonuçları, tamsayı olarak listelenebiliyorsa (Örneğin; 0,1,2,3....,10) bu rassal değişken kesikli rassal değişkendir.Sürekli Rassal Değişken
Eğer rassal değişkenin sonuçları, reel sayılar aralığı olarak tanımlanıyorsa bu rassal değişken sürekli rassal değişkendir..Örneğin; 0 ile 10 arasındaki tüm reel sayılar.
Olasılık Dağılımı
Kesikli bir rassal değişkenin tüm olası değerlerini gösteren fonksiyona veya listeye Olasılık Dağılımı adı verilir p(x). Örneğin bir zar attığımızda olası sonuçlarımız 1,2,3,4,5 ve 6’dır, her birinin gelme olasılığı ise 1/6 ‘dır.(Eğer zar hilesizse). x=1, p(x) = p(1) = 1/6 . Diğer bir örnek, kiracıların %40 nın evde bir köpek, %7sinin 2 köpek, %3 nün 3 köpek beslediğini ve %50 sinin köpek beslemediğini varsayalım. Bu durumda X =Köpek besleyenlerin, olasılık dağılımı,aşağıdaki örnekte verilmiştir.

Binom Dağılımı
En çok bilinen ve sevilen kesikli rassal değişken binomdur.Binom’un anlamını ‘iki terim’’ olarak söyleyebiliriz çünkü binom iki sonuca sahiptir.Örnek vermek gerekirse, başarılı/başarısız veya evet/hayır gibi.
Aşağıda sıralanmış olan 4 durumla karşılaşırsanız rassal değişkeninizin binom olduğunu söyleyebilirsiniz.
1.Denemeler sabit numaralardan oluşuyorsa (n)
2.Her deneme sadece 2 ihtimale sahip ise (başarılı/başarısız)
3.Başarılı olma ihtimali (p) her deneme için aynı ise 4.Denemeler birbirinden bağımsız ise, yani bir denemenin sonucu diğerlerini etkilemiyorsa.
X, n demede toplam başarılı olma sayısı olmak üzere, eğer bu 4 durumla karşılaşırsak X her bir denemenin başarılı olma ihtimali ile binom dağılımına sahip diyebiliriz.
Binom Olma Durumunun Adım Adım Kontrolü
Şimdi bir madeni parayı 10 kez atalım ve yazıları sayalım (X ) , X acaba Binom Dağılımına sahip olur mu inceleyelim.1.Denemeler sabit sayılardan oluşuyor mu?
Parayı sabit sayılardan oluşan 10 kez atıyoruz. n=10
2.Her bir deneme sadece 2 ihtimale sahip mi?
Her bir atışın sonucu yazı veya tura, yani sadece iki tane ihtimalimiz var. Eğer tura gelmesini istiyorsak bu durumda; Başarılı Olma Durumu : Tura , Başarısız Olma Durumu : Yazıdır.
Her bir atışın sonucu yazı veya tura, yani sadece iki tane ihtimalimiz var. Eğer tura gelmesini istiyorsak bu durumda; Başarılı Olma Durumu : Tura , Başarısız Olma Durumu : Yazıdır.
3.Başarılı olma olasılığı her bir deneme için aynı mı?
Bozuk paranın hilesiz olması durumunda , her bir deneme için başarılı olma ihtimalimiz p=1/2 ‘ dir.
Bozuk paranın hilesiz olması durumunda , her bir deneme için başarılı olma ihtimalimiz p=1/2 ‘ dir.
4.Denemeler birbirinden bağımısız mı?
Eğer bozuk paranın her atışta aynı yolla atıldığını farz edersek, bu sonrasında gelen sonuçların ilk atışlardan etkilenmeyeceği anlamına gelir. Yani bağımsızdır.
Eğer bozuk paranın her atışta aynı yolla atıldığını farz edersek, bu sonrasında gelen sonuçların ilk atışlardan etkilenmeyeceği anlamına gelir. Yani bağımsızdır.
- Bozuk para atma deneyemiz Binom’un bütün özelliklerini taşıdığı için bu deney için Binom Dağılımına sahiptir denilebilir
Denemelerin Sayılabilir Olması Durumu:
Eğer X turalar için sayılabilir değilse, yani denemlerimiz Kesikli bir şekilde (1,2,3,4,...) şeklinde gitmiyorsa. Saydığımız durumlardan 1.siyle karşılaşılmamış olur , bu vakada X Binom Dağılımına sahip değildir deriz.
İkiden Daha Fazla İhtimale Sahipsek :
Şimdi bir zarı 10 kez attığımızı düşünelim, yani n=10 bu kısımda 1. durumla karşılaştık. Tekrar 2. durum için inceleme yaparsak; sonuçlarımız (1,2,3,4...,6) şeklinde, yani tam 6 tane ihtimalimiz var 2 değil, bu nedenle zar atma deneyi binom dağılımına sahip değil. 2. durumla karşılaşılmadı. Yinede Binom dağılımı bu kısımda neleri kaydettiğimize dayalıdır. Yani eğer biz bu zar deneyinde tekrar 10 kez atıp bu sefer sadece 1 gelenleri kaydedersek bu dağılım Binom Dağılıma sahip olur. Çünkü eğer 1 gelirse Başarılı diğer rakamlar gelirse Başarısız sayılacak. Yani sadece iki ihtimale düşmüş olacaktır.
Denemeler Bağımsız Değil ise :
Buradaki bağımsızlık durumu eğer bir denemenin sonucu diğer bir denemeden etkileniyorsa bozulmuş olur. Şimdi bir şehirdeki yetişkin insaların Casino’larda vakit geçirmeyi iyi bulup bulmadıkları konusunda bir anket düzenleğimizi düşünelim ve 100 kişilik bir örneklem oluşturalım. Rasgele örneklem almak yerine, bu anketi 50 tane evli çifte sorarsak, yüksek bir olasılıkla çiftlerin cevapları birbirinden etkilencektir, yani gözlemler birbirinden bağımsız olmayacaktır. Bu durumda 4. durumla karşılaşılmaz. Her bir Denemenin Başarılı Olma İhtimali (p) Aynı Değil ise :
Şimdi bir torbanın içinde siyah ve beyaz olmak üzere 10 tane bilye olduğunu düşünelim. Bunların 6’sı siyah ve 4’ü beyaz.Bu torbanın içinden ilk denemede beyaz bilye çekme ihtimalim 4/10, fakat ikinci denemede beyaz bilye çekme ihtimalim aynı olmayacaktır, çünkü torabadan zaten bir çektim ve bilye sayısı şu anda 9 ve çektiğim bilyenin de beyaz olduğunu varsayarsak, ikinci denemde beyaz çekme olasılığım 3/9 olacaktır. Yani başaralı olma ihtimalim değişti ve 3. durumla karşılaşılmadı.Binom Formülü İle Olasılık Hesabı
X’in Binom Dağılımına sahip olduğunu tanımladıktan sonra büyük ihtimalle bu X rassal değişkenin olasılıklarını bulmak isteyeceksiniz.İyi haber bu olasılıkların hepsini sil baştan bulmanıza gerek yok, n ve p değerleri ile kurulmuş olan binom formülünü kullanabilirsiniz.
P(x) :


ÖRNEK:
İşe giderken geçmek zorunda olduğun 3 tane trafik ışığı olduğunu varsayalım. X de senin yolunda olan kırmızı ışıkların sayısı olsun .Kaçtane durumda 2 tane kırmızı ışığa denk gelebilirsin? İhtimalleri değerlendirmeye başlayalım, ilk ışıkda yeşil diğer ikisinde kırmızı, oratadakinde yeşil diğerlerinde kırmızı veya ilk ikisi kırmızı sonra yeşil.
Şimdi Kırmızı=K ve Yeşilde=Y olsun budurmda karşılaşabileceğimiz 3 ihtimal;
YKK -
KYK -
KKY
Şimdi ilk önce kombinasyonumuzdan başlayalım.Yani bu bilgiler doğrultusunda kaç farklı durumla karşılaşırız onu bulalım. Aslında az önce YKK,KYK,KKY olarak bulduğumuz 3 durumu kombinasyon formülü ile bulacağız.

Şimdi Binom hesaplamalarına başlamadan önce adım adım bu deney binom Dağılımına uyar mı onu inceleyelim:
1.3 tane denememiz bulunmakta (n=3)
2.Her bir denmeye iki ihtimale sahip başarılı(kırmız) ve başarısız(sarı ve yeşil)
3.Denemeler bir birinden bağımsızlar
4.Ve her bir tarfik ışığı zamanın %30’unda kırmızı yanmakta yani p=0.30.
Yani X = Kırmızı yanan trafik ışıkları normal dağılıma sahip. Ve 1 – p = kırmızı ışık yanmama olasılığı = 1 – 0.30 = 0.70


Binom - Koşullu Olasılıklar
Az önceki Trafik Işığı örneğinde olası X’in olasılığı o’dan n’e kadar olan herhangi bir değere eşitti.Bu kısmda aradığımız olasılığın küçük, büyük veya arasında olması durumundan bahsedeceğim.
Örneğin; azönceki örnekte bulduğumuz 4 tane olasılık vardı :
1.Hiç kırmızı ışığa denk gelmeme : p(0) = 0.343
2.1 kırmızı ışığa denk gelme : p(1) = 0.441
3.2 kırmızı ışığa denk gelme : p(2) = 0.189
4.3 kırmızı ışığa denk gelme : p(3) = 0.027
●
Şimdi p(x > 1) olasılığını bulalım.Yani 2 kırmızı ışığa veya 3 kırmızı ışığa denk gelme olasılığımız.
Bu olasılığı p(2) + p(3) toplamına eşittir. 0.216
P(1≤x≤3) olasılığmız ise = 0.441 + 0.189 + 0.027 = 0.657
Binom Ortalama ve Standart Sapma
Eğer X n sayıda deneme ile Binom Dağılımına ve her bir deneme için p olasılığına sahip ise;
Örneğin; 100 kez madeni para atıyoruz ve X turaların sayısı olsun. X ; n=100 ve p=0.50 olmak üzere normal dağılıma sahiptir.
1.Ortalaması : : μ=np=100.(0.50)=50 Yazı
2.Varyansı : σ^2=np(1-p)=100(0.50)(1-0.50)=25
3.Standart Sapma : σ=√(np(1-p))=√(100(0.50)(1-0.50) )=5